![]()
 Background on the Healthcare.gov Technology Problems
Background on the Healthcare.gov Technology Problems
My blog post on October 1st, Healthcare.gov is a Technological Disaster, described my experience using the Affordable Care Act’s Healthcare.gov website on its first day. Based on my experience, I could tell the Obamacare site was a technical mess independent of the number of users on the system. However, “Too many users” was a convenient and politically positive excuse the contractors and administration attributed to the failure of the website. It took about a week before the press began to understand that wasn’t the case. Because of my blog post, I ended up in a New York Times article, the national broadcasts of CBS, CNN and Fox News, and a few radio shows (links are in my prior blog post). I was also invited by the House Energy and Commerce Committee staffers on Capitol Hill to meet them to help them better understand what was and wasn’t working and why.
Solutions for Improving Healthcare.gov
I dislike complainers who don’t offer solutions, so I feel obligated to offer some constructive ideas for creating a functional Healthcare.gov website. I’m not being paid to work on the Healthcare.gov web site and don’t have the actual specifications of what needs to be created, but based on my experience building database solutions and understanding load balancing, I offer the following ideas to consider.
Understanding the Buying Process for Health Insurance
It’s important to understand what the web site should do. The primary mistake the designers of the system made was assuming that people would visit the web site, step through the process, see their subsidy, review the options, and select “buy” a policy. That is NOT how the buying process works. It’s not the way people use Amazon.com, a bank mortgage site, or other insurance pricing sites for life, auto or homeowner policies. People want to know their options and prices before making a purchase decision, often want to discuss it with others, and take days to be comfortable making a decision. Especially when the deadline is months away. What’s the rush?
The existing process acts as if a retail website asked for your credit card number before showing what you could buy and their prices. Almost all sites let you browse without creating a user name. Retailers want you to see what’s available as quickly and easily as possible. People often visit multiple times before buying. Only after making a purchase decision should personal information be collected to complete the transaction.
The web site needs to reflect this and support a more common buying process.
Conceptual Overview
Here’s an overview showing three distinct processes that flow into each other (or people buy a policy at their step and leave the system). A critical part is offering a comparison matrix at each level so consumers can quickly see the differences between the insurance policies.
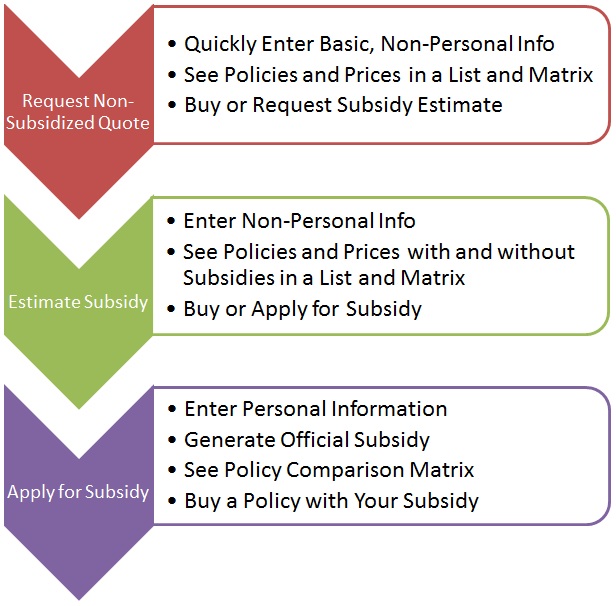
(click for larger image)
-
The first one gives policy options and non-subsidized quotes. People can click to purchase the policy from the insurance company. If so, they leave Healthcare.gov and the government is no longer involved.
-
The second provides a subsidy estimate and uses the same display as the first but with and without subsidized prices. People can also click to buy the policy without a subsidy and leave the system, or they can officially apply for a subsidy.
-
The third is the actual application for the subsidy and the only path which collects Personally Identifiable Information (PII). Higher security is necessary for this.
The first two do not require PII and would not require high security. That means a commercial cloud service such as Microsoft Azure could be used to host the site and adjust to high traffic loads. It would support people shopping and browsing multiple times before buying without the need to invest in hardware or bandwidth.
With this improved design, only a small portion of the site’s traffic would be in the final subsidy application portion. That can be isolated with high security and for much lower volumes of users since people would only apply once. Hassling people at this stage with lots of personal questions is acceptable since people are serious about purchasing.
User Experience Goals
These are some objectives for creating a great user experience:
- Quickly get the unsubsidized insurance rate quotes and policies (no login required)
- Easily compare among insurance policies based on features and price
- Easily select and subscribe with an insurance company without a subsidy
- Quickly receive an estimate of a subsidy without having to provide personally identifiable, confidential information
- Easily compare among insurance policies based on features and subsidized prices
- Do not ask unnecessary questions such as race that don’t impact plans, prices, or subsidies
- Formally apply for the subsidy (login and personal information required)
- Select a subsidized policy and pass the appropriate information so the insurance company can validate the subscriber’s information and receive the subsidy
- Once policy options are offered, allow users to create a login to save their inputs, and get back into the system to recover their work-in-progress. This would be required with the formal subsidy application but not necessary for the other options.
Technical “Back Office” Goals
- Performance: The system should move people through the process as quickly as possible.
- Collecting Information: It should not ask for any information that’s not required for generating the policy options and prices.
- Fewer Screens: Rather than having one screen per question, multiple questions should be asked in as few screens as possible. People know how to scroll. Extra screens should only be added if they depend on answers from previous screens.
- Data Security: The first part of data security is to NOT collect sensitive information. Sensitive information should only be collected from people actually applying for the subsidy.
- Data Integrity: All database changes need to be in transactions with commitments and rollback on failure. Situations where accounts are partially created with a valid user name and no account details should never occur.
- No Other Connections During Data Entry: The system should not be connecting to other data sources while the user is entering data. Just collect the data.
- Offline Processing: Once the user enters all their data for a subsidy quote, a separate system processes the applications and interfaces with the other systems to validate the data and calculate the subsidy. By separating this process from the user’s online experience, problems with connections to other systems do not impact the user.
- Email Notification: Once a subsidy is calculated, an email is sent to the user inviting them to log into the system to see their options
- Notification to Insurers: Web pages and web services to allow real-time views of the status of applications selecting the insurer’s policies.
- Commercial Cloud Hosting: Using a commercial cloud platform would provide automatic scalability to meet fluctuating levels of users without having to make hardware purchases. By eliminating the need to collect and store sensitive user data for most of the website, commercial cloud hosting and its benefits are available without security concerns.
Oversight Goals
Management and interested parties should have system dashboards:
- Real-time Displays: Monitor user progress with summary tables and graphs showing the status of people moving through different stages of the system.
- Basic Business Intelligence: Summary and drill-down details by state, date, hour, etc.
- System Transparency: Provide a public view of some data in a cached mode (updated daily or hourly, but not real-time).
Design Overview
Here is how the goals could be implemented for the Healthcare.gov web site:
- The initial form asks people to select their state. If the visitor is in a state that has their own system, ship them to those sites, otherwise proceed with the next step in the federal system
- Collect the information necessary to create the unsubsidized options. I was told there were five or so pieces of information necessary to generate the unsubsidized rates (e.g. gender, year of birth, family status, smoking status, etc.)
- Display the available plans with options to compare and filter them easily based on plan level (gold, silver, bronze, etc.), provider, price, etc. Should be similar to retail web sites like Best Buy or Staples showing different products and their features in a matrix comparison, with buttons to get more details and a button to select one to buy. One would expect users to come to this site multiple times over multiple days to learn about their options before making a purchase.
- An option to save the inputs. This would be the first time to create a simple account to collect user information (which does not include things like social security numbers, birthdates, or names). A simple user name (email address) and password, with a standard email confirmation that doesn’t have a time limit. This would allow users to get back to the previous screen without re-entering their data.
- An option to get a subsidized price estimate. If the person chooses this option, they create a simple account because highly sensitive information will not be collected. The account is simply to retrieve the user’s entries. The user provides the information necessary to calculate the prices without having to lookup data from government sources. The user can enter their values for income and whatever other factors impact generating a subsidy estimate. Just like bank web sites let you enter basic information to get a mortgage or car loan rate before you apply, Healthcare.gov should do the same. This would allow the site to create quotes quickly without having to bog down or wait for the other sites such as the IRS, Experian, etc. This minimizes the impact of too many users. Once the estimated subsidies are calculated, a display similar to #3 above would show the options.
- Finally, applying for the subsidy. Once someone decides they want a particular policy, they can officially apply for a subsidy. This is the first time personal data needs to be entered. The system should collect the data as quickly as possible without having to validate the information while the user is entering it. Once all the data is collected, the user is informed via email when the subsidy calculation is ready.
- A separate background process calculates the subsidy requests and looks up the necessary data from the different sources. If any of those linked systems is unavailable, it’s no big deal since it doesn’t impact the user on the web site. The user is already gone and waiting for an email. Once the calculation is generated (or if it couldn’t be generated), the user is notified via email and they can view the results by logging back into their account.
For management, there should be dashboards with tables and graphs showing what’s happening. No more excuses of not knowing how many people are in each phase of the process, how many have received quotes or enrolled, etc. For transparency, some of this information should be publicly available updated at least daily.
Conclusions
I’m not sure whether the people designing and developing the site will find these suggestions helpful. There’s obviously lots of details not included in my proposal, but I’m confident my basic design is a significant improvement over the original site. It would provide a better user experience, be much easier and faster to develop, easier to test, and more scalable and secure. Was it that tough to envision earlier?
Let’s remember, this website remains the automation of a paper form. It’s not as hard as providing healthcare.
 Microsoft Access 2013 Features
Microsoft Access 2013 Features







