Total Access Emailer is the most popular email program for Microsoft Access. Easily send personalized emails to everyone in your table or query. You can even attach filtered reports as PDF files for each contact.
Total Access Emailer is the most popular email program for Microsoft Access. Easily send personalized emails to everyone in your table or query. You can even attach filtered reports as PDF files for each contact.
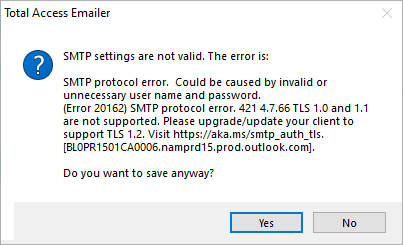
Total Access Emailer uses industry standard SMTP to send emails bypassing the limitations of Outlook and sending messages from multiple FROM addresses. A popular SMTP server is Google Gmail with their free and paid Workgroup accounts.
Google Gmail SMTP Protocol Changed
 Google sends emails with its SMTP server at smtp.gmail.com. A few years ago, to increase security, Google required users to explicitly set Gmail accounts to allow Less Secure Apps for this feature.
Google sends emails with its SMTP server at smtp.gmail.com. A few years ago, to increase security, Google required users to explicitly set Gmail accounts to allow Less Secure Apps for this feature.
Starting June 1, 2022, Google no longer supports Less Secure Apps for sending SMTP emails which they consider to be a security hole. To address this, they offer two options.
- Creating and using a Gmail App Password
- Using Google Gmail API OAUTH 2.0 protocol which is ideal for organizations with paid Google Workspace accounts
Total Access Emailer and the Google Gmail SMTP Server
We are pleased to announce the release of updates to Total Access Emailer that support the new Google Gmail protocol requirements.
Whether you run it as a Microsoft Access add-in or through its VBA Runtime Library, Total Access Emailer supports using a Google App Password or a Google email API Client ID and Secret ID with OAUTH 2.0 authentication.
From the Options form’s SMTP Settings tab, there’s a new section for Gmail Authentication which launches a Wizard to load your account:
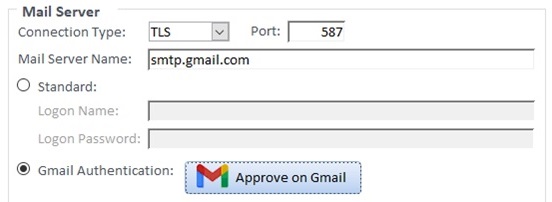
With the Professional Version’s royalty-free VBA runtime library, you can set this up and deploy it to others, or your users can authenticate it with their own Google Client account using a new procedure to support this.
Instructions for configuring Google Gmail SMTP with Total Access Emailer are here:
New Versions of Total Access Emailer
These versions are now shipping with support for the increased security protocols for Google Gmail and Microsoft Office 365, plus many other New Features:
- Total Access Emailer 2022, version 22.0 for Access 365, 2021, and 2019
- Total Access Emailer 2016, version 16.81 for Access 2016
- Total Access Emailer 2013, version 15.81 for Access 2013
- Total Access Emailer 2010, version 14.81 for Access 2010
All versions include Access 32 and 64-bit support. Existing customers are eligible for discounted upgrade prices.